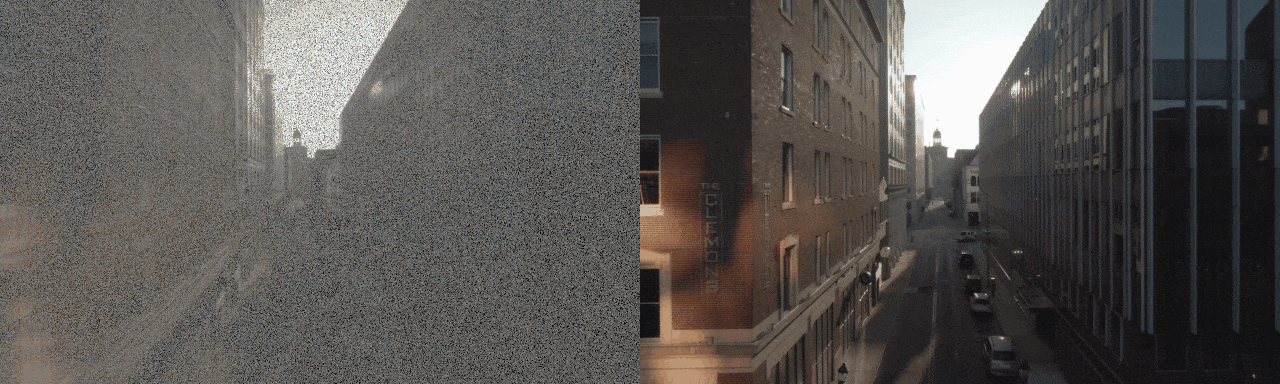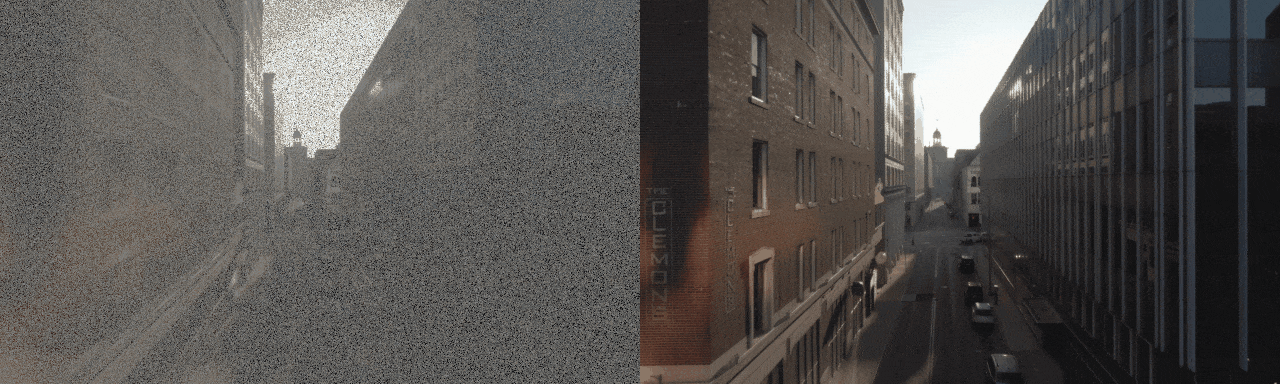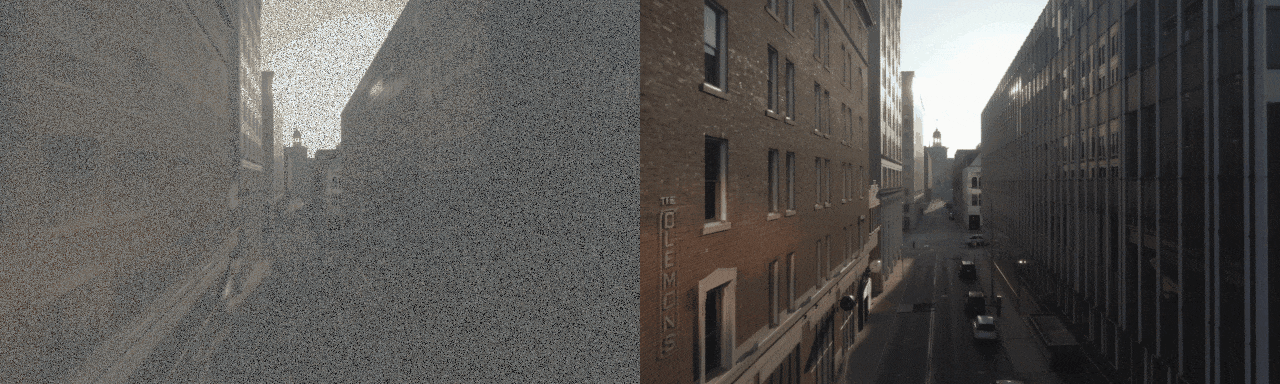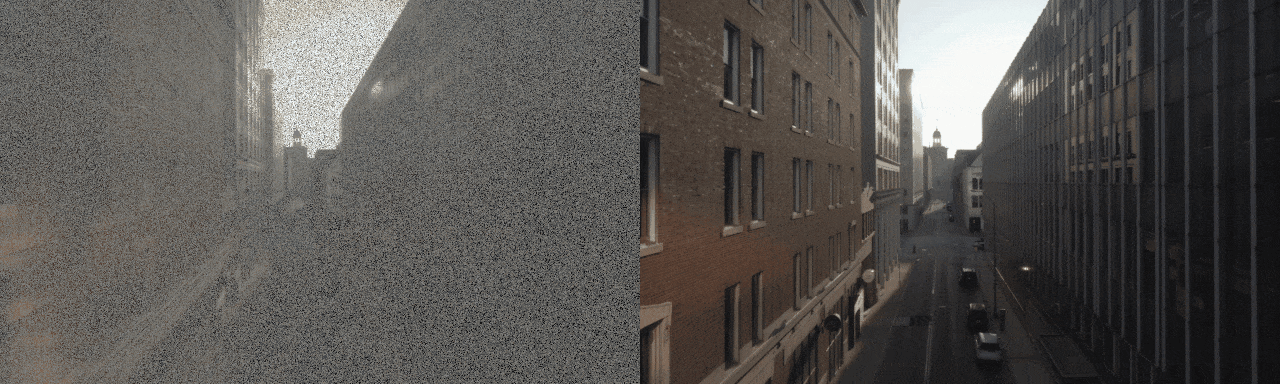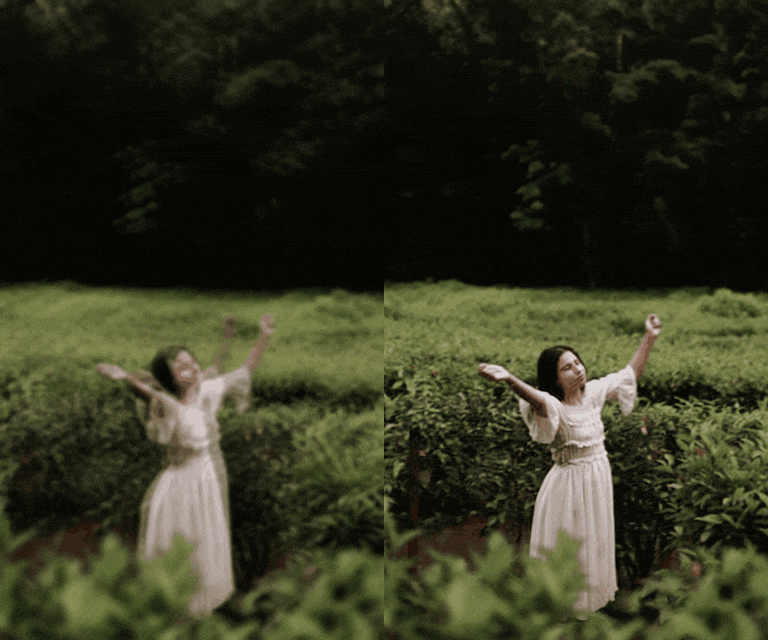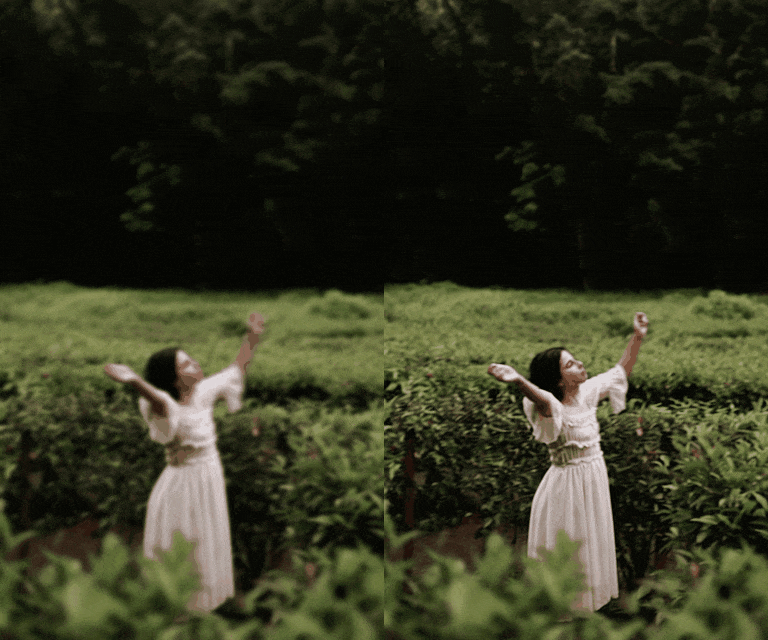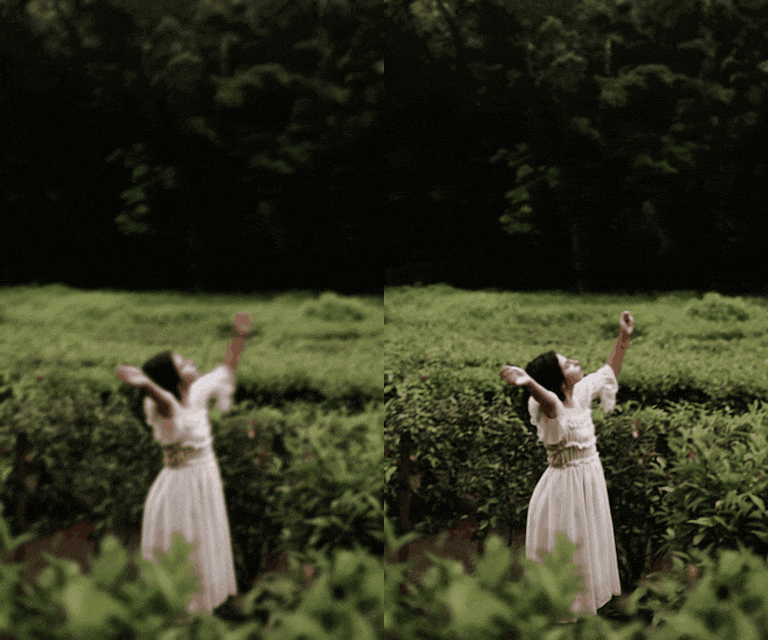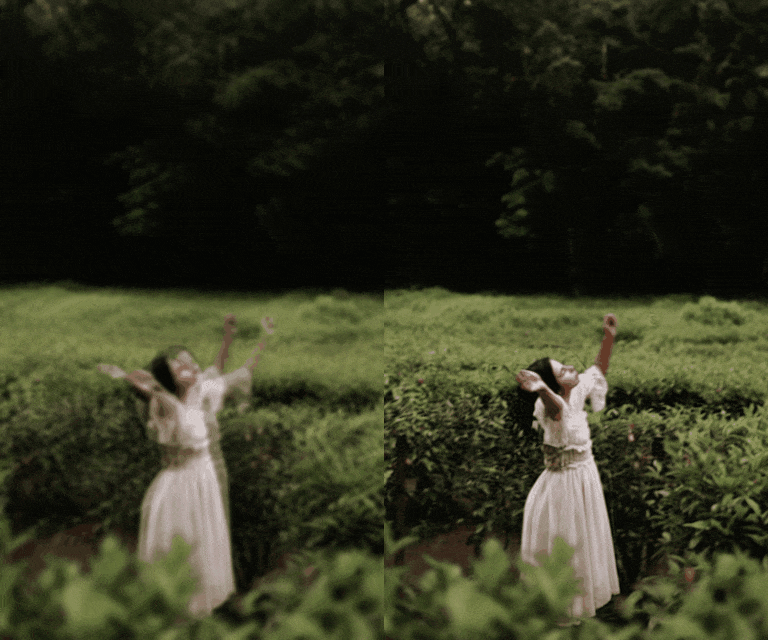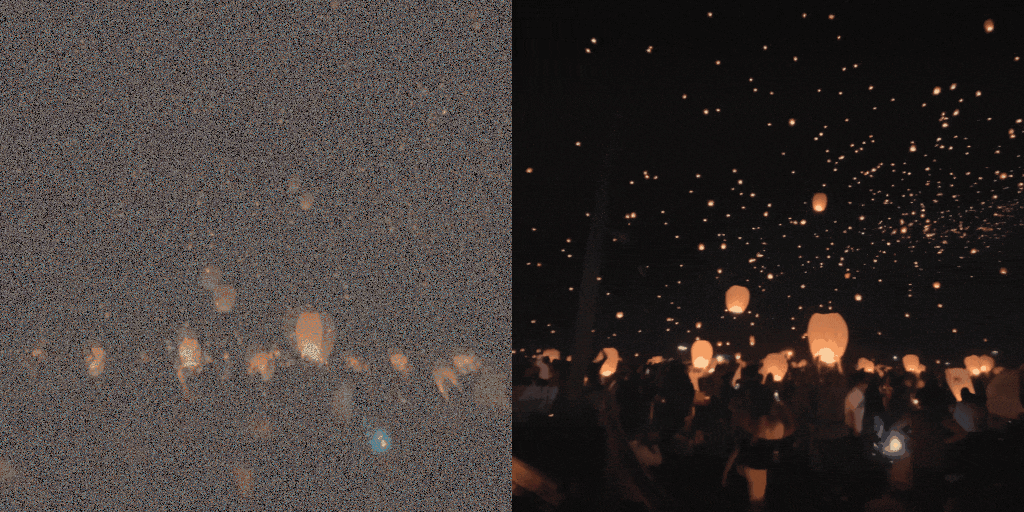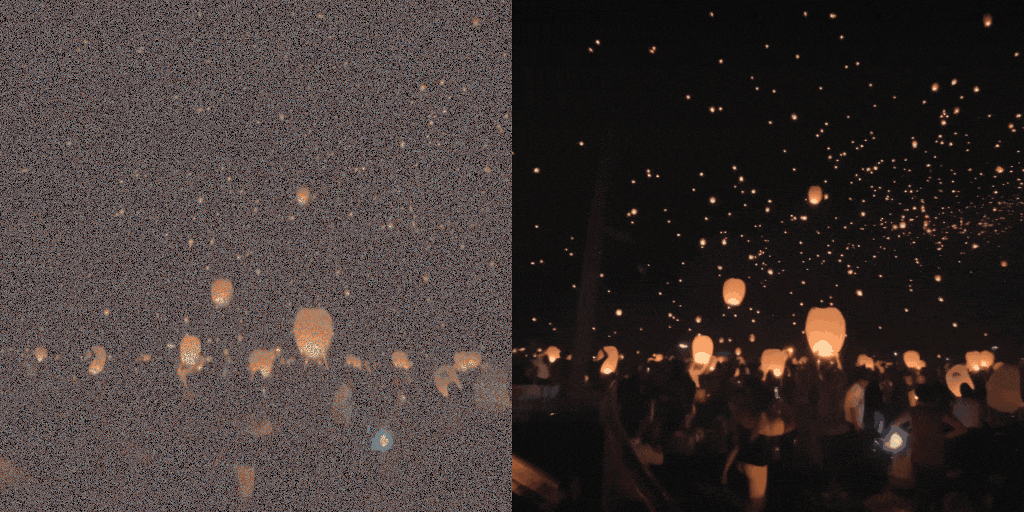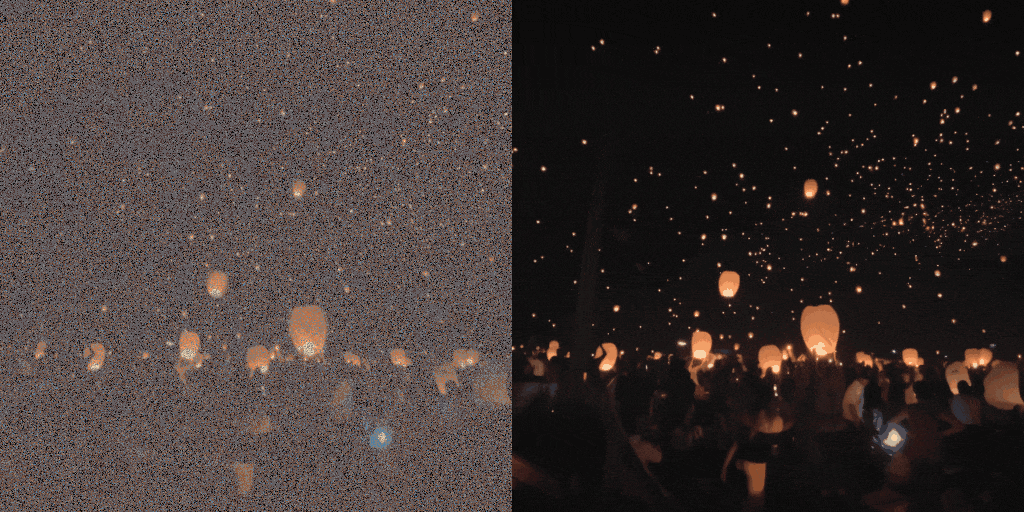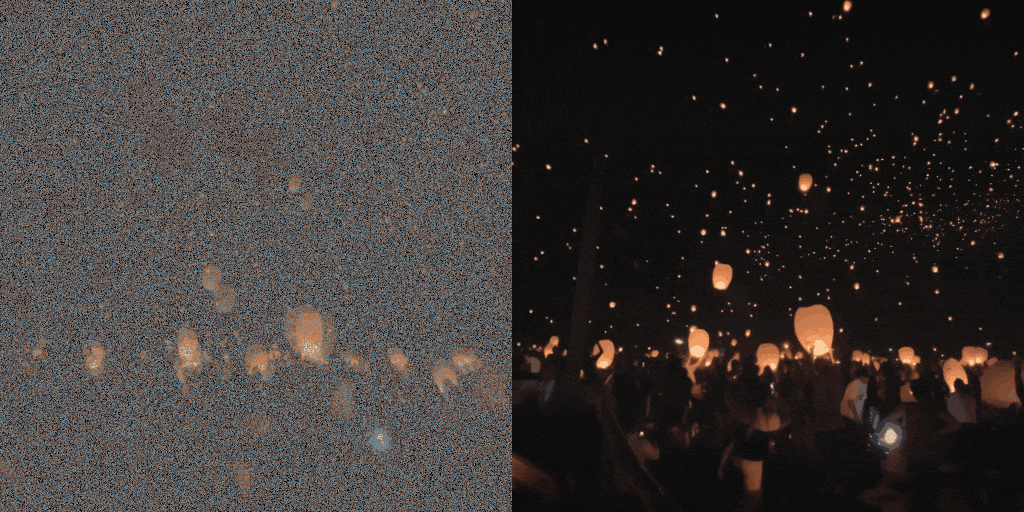Diffusion model-based inverse problem solvers (DIS) are now leading techniques for solving inverse problems.
Recent extensions have adapted these models to solve video inverse problems using image diffusion models,
but they face limitations such as restricted resolution (256x256) and dependency on additional pre-trained modules like optical flow estimators and task-specific restoration models.
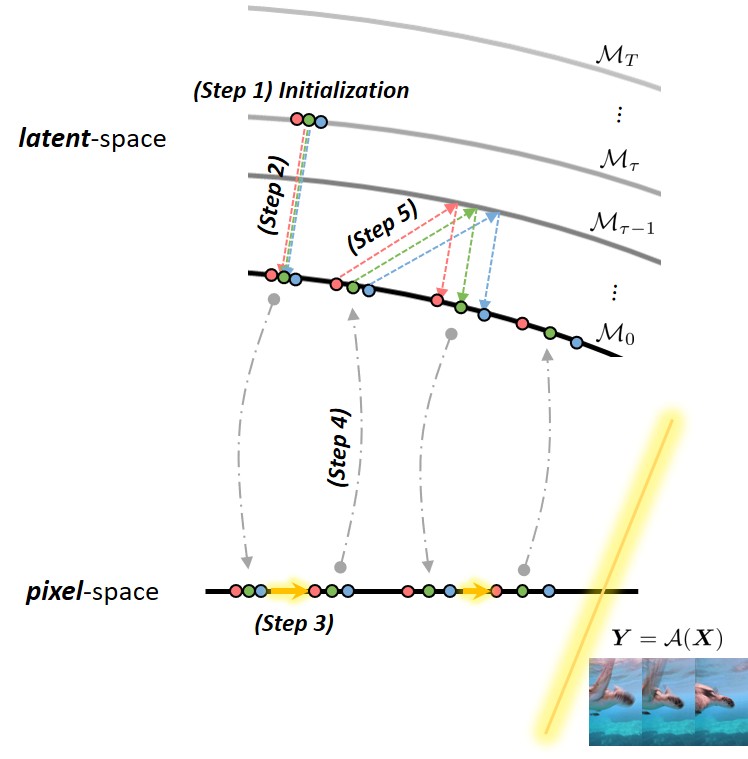
In response, we introduce a novel framework for solving high-definition video inverse solver using only latent diffusion models.
For efficient high-resolution processing on a single GPU, we introduce a pseudo-batch consistent sampling strategy.
Additionally, to enhance temporal consistency, we implement pseudo-batch inversion, an initialization method that incorporates informative latents from the measurement frame.
|
Ours 😁 |
| Scalability |
Supports muiti ratio & high-resolution reconstructions |
| Memory & sampling time effieciency |
Requires 13GB VRAM for 25-frame videos, within 2.5 min. |
| Accessibility |
Using open-sourced latent diffusion model (SDXL) |
By integrating with SDXL, our framework achieves state-of-the-art video reconstruction across a wide range of spatio-temporal inverse problems,
including complex combinations of frame averaging and various spatial degradations, such as deblurring, super-resolution, and inpainting.